让 AI 真正"看见"网页
想象一个场景:你告诉电脑"帮我把这个网页上所有关于 AI 的新闻整理成表格",然后它就真的打开了浏览器、浏览了页面、提取了信息、生成了你想要的表格——整个过程不需要任何 API,也不需要你写一行爬虫代码。

这就是 Browser Use 在做的事情。作为一个开源项目,它让 AI 代理能够像人类一样操作真实的浏览器——点击按钮、填写表单、滚动页面、提取数据。目前它在 GitHub 上获得了超过 95,000 颗星,是浏览器自动化领域增长最快的项目之一。
为什么重要?
传统的网页自动化工具(如 Selenium、Puppeteer)需要你精确地告诉它每一步做什么:"找到这个 CSS 选择器,点击它,等待 2 秒,提取那个元素的内容"。这种方式脆弱且难以维护——网站只要改一下 class 名,你的脚本就报废了。
Browser Use 的突破在于:你只需要告诉它你要什么,它自己决定怎么操作。它利用 AI 模型的眼睛来"看"页面,理解页面的结构和内容,然后做出决策。
这意味着:
- 不再依赖选择器——AI 通过视觉和文本理解元素
- 自适应变化——网站改版了?AI 仍然能找到它需要的东西
- 减少 90% 的代码量——从"如何做"变成"做什么"
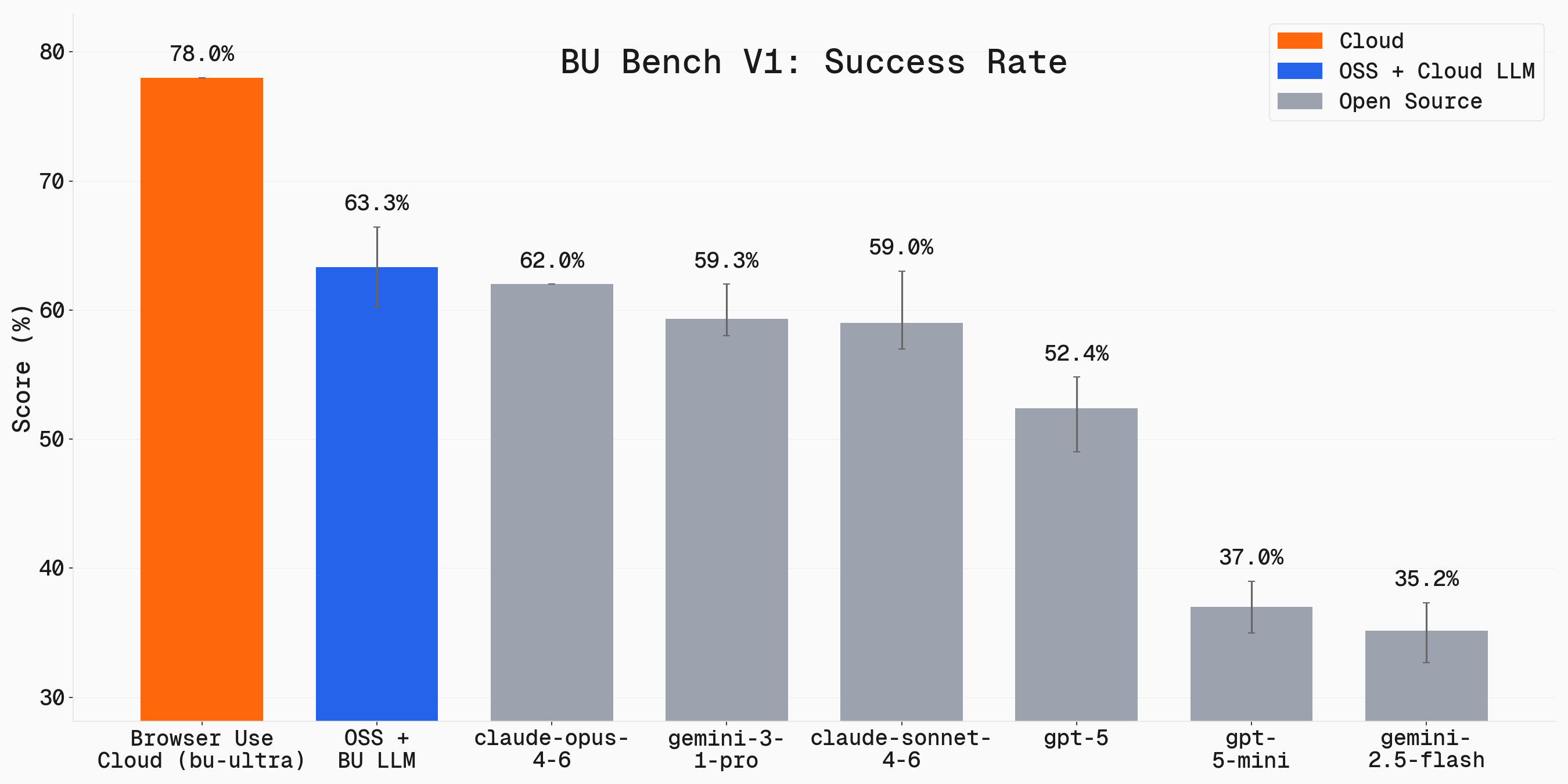
各 LLM 在 Browser Use 基准测试中的表现对比
快速上手
安装非常简单,一行命令:
pip install browser-use然后你需要设置 LLM API key(支持 OpenAI、Anthropic Claude、Google Gemini 等):
export OPENAI_API_KEY=sk-...使用实例
实例 1:自动搜集信息
假设你需要从某个百科页面获取特定数据:
from browser_use import Agent
import asyncio
async def main():
agent = Agent(
task="打开维基百科上关于「人工智能」的页面,提取前三个重要里程碑及其年份",
)
result = await agent.run()
print(result)
asyncio.run(main())Agent 会自动打开浏览器、搜索关键词、阅读内容、提取你所需的信息。
实例 2:跨网站数据对比
比较多个电商网站的商品价格:
from browser_use import Agent
import asyncio
async def main():
agent = Agent(
task="访问京东和淘宝,搜索「iPhone 16 Pro 256GB」,比较两边的价格和评价数",
)
result = await agent.run()
print(result)
asyncio.run(main())Agent 会在两个网站间切换执行,最终给你一份对比报告。
实例 3:表单自动填写
自动化完成表单提交流程:
from browser_use import Agent
import asyncio
async def main():
agent = Agent(
task="登录 GitHub,创建一个名为 test-repo 的新仓库,设置为公开",
)
result = await agent.run()
print(result)
asyncio.run(main())核心特性
- 基于 Playwright——底层使用微软的 Playwright 框架,支持 Chrome、Firefox、Safari
- 多 LLM 支持——可与 OpenAI、Claude、Gemini、本地模型等对接
- 可自定义动作——除了内置动作,还可以注册自己的浏览器操作
- 持久化上下文——支持 Cookie 保持登录态、历史记录追溯
- 人类干预模式——遇到困难时可以请求人类帮助,然后继续执行
"Browser Use 代表了一种新的范式转变:从告诉计算机如何做,到告诉计算机做什么。这不仅仅是自动化工具的进化,而是人机交互方式的革命。"
适用场景
- 数据采集——从没有 API 的网站抓取信息
- 自动化测试——用自然语言编写测试用例
- 工作流自动化——自动完成重复的网页操作
- AI Agent 工具——作为 AI 助手的浏览器操控能力
- 原型验证——快速验证一个网页功能是否可用
总结
Browser Use 是一个让人眼前一亮的产品。它将 LLM 的理解能力与浏览器操控能力结合,打开了一扇新的大门。无论是开发者想构建自动化工具,还是普通用户想减少重复操作,都值得一试。
▶ 前往 GitHub 仓库 · 已有 95,000+ 星标记